‘Learning’ the Stochastic Gradient Descent Algorithm

When it comes to machine learning and computers being able to learn and recognize patterns — similar to what our brains do, (which is why ML/AI fields are so related to neuroscience) we want to be able to increase the accuracy and efficiency of our prediction algorithm. This is so that the prediction gets better and better, closer to the target value we are aiming towards achieving.
Let’s compare this situation to a more human-related real life scenario. Suppose you are studying for an exam. You have a set study plan, and followed the points in your plan to prepare. Unfortunately, you weren’t too satisfied with your result, since your exam result was way off the targeted score you wanted to achieve. So, what do you do? Well, you would want to make some adjustments to your study plan in order to prepare for your next exam effectively and efficiently.

You would want to make adjustments based on what you think you should have worked on more, such as:
- covering more broad topics next time,
- reading over applications,
- practicing more problems..etc.
You are doing this because you learned from your past experience, and are making some changes to perform better, and get a better result.
This is exactly what optimization in machine learning is all about. It’s about making these small adjustments to see if an algorithm’s accuracy is improving. The algorithm wants to get as close to the target value, and optimization techniques can allow us to choose and make adjustments to our paramaters of our machine learning model (also known as the weights), so the algorithm performs better next time.
One of the most well known optimization methods used today is called the Stochastic Gradient Descent (or SGD in short). How does this method work, and what certain adjustments does it make to our algorithm?
Before we add the word “Stochastic”
Before we dive into what Stochastic Gradient Descent is, lets take a look at what the term “Gradient Descent” means.
When we want to increase the accuracy of a machine learning algorithm, we are looking for our error difference. What is the difference betweeen the target value and the predicted value from our model?
Let’s say we had a model that outputs a numerical real valued number based on some arbitrary inputs. The predicted value (the value that is produced based on the model parameters) is 1.45. The actual target value is 3.32. This doesn’t look like a good ‘learning’-based model, since the target and predicted values aren’t too close. The error difference is then 3.32–1.45 = 1.87. We want the target value to be close to the actual value, so how do we get a good understanding of whether the algorithm is functioning terribly or well?
Cost Function
We can use a Cost Function to analyze the model’s ability to understand and learn patterns and relationships between inputs and outputs. A cost function is usually a function of the error difference, and our goal in machine learning problems is to MINIMIZE the cost function. There are many cost functions we can use to optimize models. Examples are Mean Squared Error (MSE), Mean Absolute Error (MAE), and a lot of other more math-heavy trickier ones :)
Now we might be thinking — why can’t we just work with our error difference and minimize our error difference itself? Why do we have to work with a cost function? Our error function can also be negative — in this case it is ‘minimized’ in terms of the value, but, there still exists a huge difference between our predicted and actual values. So this is why we are going to instead focus on some function of our error, rather than just the error difference itself.
For instance, if we are focusing on improving a single linear neuron’s output prediction, (in a neural network), we will want to obtain a set of weights which will minimize the cost function. This means we will have to find the minima of the function — where is the lowest point of this particular function?
This neuron has three inputs and 3 associated weights for each feature. The output is then the dot product of the weights and inputs, which is then passed into an activation function, such as ReLU. Now, how would we essentially train our model to adjust our weight parameters to improve the accuracy? Since we use functions to get to the output of this neuron, we need to do just the opposite to backpropagate, i.e. go back change the weight parameters to perform better. This means we are gonna get into derivatives .
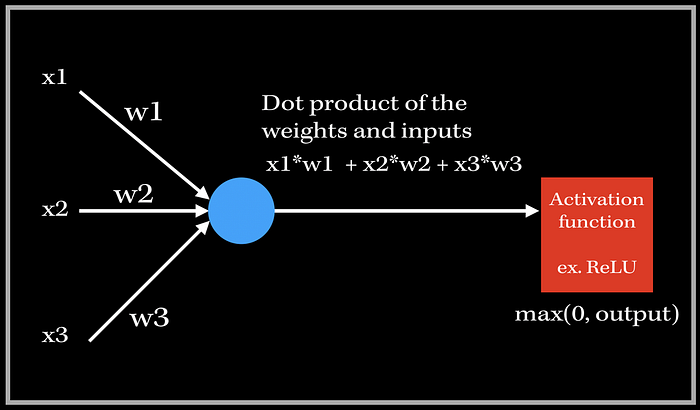
So we know that our cost function is technically a function of the weights, since computing the difference between the target and predicted value involves the predicted value, which involves the dot product of the weights and inputs. The main goal of gradient descent is to iteratively decrease the function of weights/cost function such that we find a set of weights for where the accuracy is maximized.
The Gradient and the Descent
We can first set arbitrary values to our weights, for instance, starting from 0. Then, from that point, we need to find out which direction to go towards in order to reach the minimum value of the cost function. The gradient of the cost function tells us exactly that. The gradient, also denoted with a upside down triangle, represents the slope of the function with respect to each weight. The gradient of the cost function is basically a vector of partial derivatives with respect to each weight (ex. w1, w2,..etc).
*Note: We are assumming this cost function is a strictly convex function, i.e. a function which has no more than 1 minimum point.*
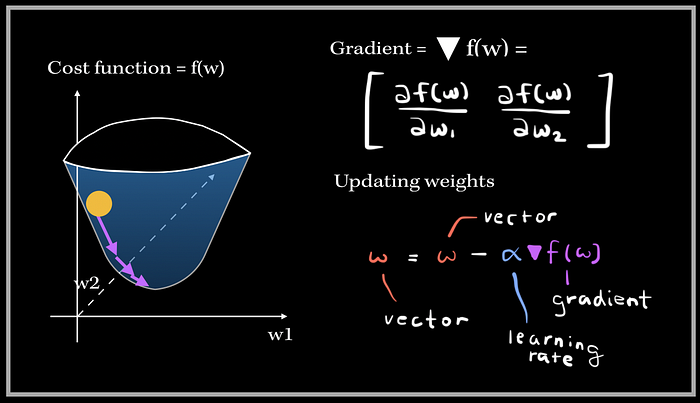
When we are updating our weights, we subtract the gradient multiplied by the step size with the old set of weights. The w in the equation above is basically a vector of weights, in this case a vector of two weights w1, w2. The gradient is also a vector with the partial derivatives with respect to w1, w2. This process of updating the weights iteratively happens until the gradient is at or at most close to 0 (this will indicate it’s at a minima).
The step size basically tells us how fast is the iterative process towards convergence. For instance, a small step size will slow down the convergence process, and a large step size might lead to an infinite amount of iterations..,divergence, which is not good! That is why it is so important to find the right step size amount.
Back to the ‘Stochastic’
Ok, so now that we looked into Gradient Descent, what does the term “Stochastic” mean? Stochastic is all about randomness. What can we do to this algorithm that involves randomness though?
Though the Gradient Descent algorithm is very effective, it isn’t too efficient for huge amounts of data and parameters. The Gradient Descent algorithm updates weights only after only one complete pass of the training dataset. It would have to compute the gradient after every iteration (after one pass of all the training samples). With a large amount of features and weights, this can be computationally exhaustive, and time consuming.
The Stochastic Gradient Descent, or SGD introduces a sense of randomness into this algorithm, which can make the process faster and more efficient. The dataset is shuffled (to randomize the process) and SGD essentially chooses one random data point at every iteration to compute the gradient. So instead of going through millions of examples, SGD using one random data point to update the parameters. This computationally makes the algorithm a bit more efficient. Consequently, it can lead to excessive ‘noise’ on the pathway to finding the minimum. For example:
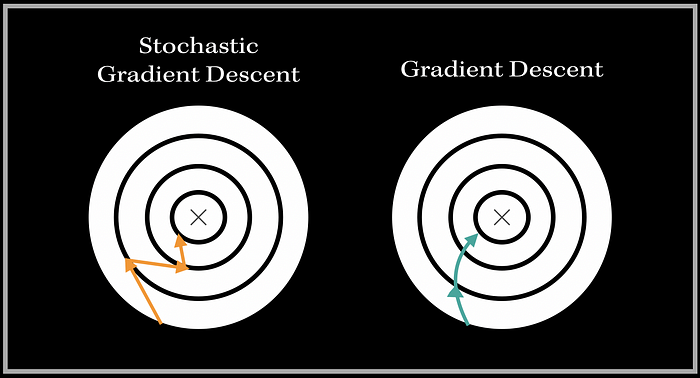
The trajectory towards the minimum looks very different for both of these variants of Gradient Descent. For SGD, the path is heading towards the minimum with harsh, and abrupt turns (because we are using random samples to update weights), and the path for the Gradient Descent algorithm is more smooth, and direct since we are using all of the training samples to compute the gradient. This is a very interesting aspect that looks visually different for both the optimizers.
Applications
The Stochastic Gradient Descent algorithm is one of the most used optimization algorithms in Machine Learning. It is very popular in deep learning and neural networks as well!
The Gradient Descent Algorithm has applications in Adaptive Filtering (learning based systems), and is used to optimize the filter’s weights to minimize a cost value. An example of a particular Adaptive Filter is the Noise Cancellation algorithm in our headsets!! :) Thank you! 😊
Links for more information: https://en.wikipedia.org/wiki/Stochastic_gradient_descent
Originally published at https://rushiblogs.weebly.com.
